
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- formula
- 부트캠프후기
- explode()
- php
- DOM
- 객체지향
- JDBC
- 배열
- Java
- oracle
- strpos()
- MySQL
- INSERT
- JavaScript
- 정규식
- 현대이지웰java풀스택개발자아카데미6월
- dao
- node.js
- myshortcut
- 오류
- 깃허브
- mybatis
- react
- error
- jQuery
- DTO
- 멀티캠퍼스it부트캠프
- ES6
- axios
- 노션
- Today
- Total
코딩짜는 일상
[현대이지웰 Java 풀스택 개발자 아카데미 6월] TIL 20차 - 프로젝트에서 MyBatis 사용하기2 (feat.Oracle) 본문
[현대이지웰 Java 풀스택 개발자 아카데미 6월] TIL 20차 - 프로젝트에서 MyBatis 사용하기2 (feat.Oracle)
Remily 2025. 12. 1. 00:29📚 서론
지난주에 이어 프로젝트에서 MyBatis로 기능을 구현할 때 php와의 차이점을 정리해 보겠습니다.
php는 디테일하게 언급 안 할거라 써보신 분들을 독자로 가정하고 쓴 글이라고 보시면 될 것 같습니다.
주인공은 어디까지나 MyBatis와 오라클이니까요!

🎷 INSERT 직후 기본키(Primary key) 가져오기
현재 저희 프로젝트의 상품 데이터에는 일반적인 상품 데이터 외에도
그 상품에 포함되는 성분에 대한 데이터도 저장되고 있습니다.
성분 데이터는 저희 프로젝트의 핵심이라
상품 데이터 외에도 여러 테이블과 JOIN되어야 하기 때문에
별도의 매핑 테이블을 만들어 JOIN할 때 참조로 사용하고 있습니다.
그래서 새로운 상품을 등록하려면,
먼저 상품을 등록한 후에 기본키(Primary key)를 가져와서
성분 데이터와 매핑해주는 과정을 거치는 것이 일반적입니다.

하지만 이 방법은 상품 등록에 2번의 과정을 거쳐야하므로 매우 번거롭습니다.
그래서 주로 등록과 동시에 기본키를 가져와서
매핑까지 한 번에 등록하는 식으로 작업을 진행합니다.

php + MySQL 조합에선 INSERT 쿼리를 실행한 직후 mysql_insert_id(); 함수를 사용하여
자동 증가한 기본키 값을 받아오는 방식을 사용했었는데요.
보안 이슈가 있어서 PHP7 이상에선 제거되었고
7 이상부턴 PDO의 $pdo->lastInsertId()를 쓴다고 합니다.
그럼 스프링 부트 + MyBatis + 오라클 조합에선 어떻게 가져올까요?
1️⃣ <selectKey> 태그 활용 - 시퀀스 사용
오라클에는 MySQL의 AUTO_INCREMENT가 없고
대신 숫자를 자동으로 만들어주는 시퀀스(sequence)를 만들어서 그 값을 받아와 사용합니다.
Oracle 12c 부터는 GENERATED 구문을 추가해서
테이블 생성시 시퀀스도 자동으로 생성할 수 있는데요.
기본키가 될 필드명과 자료형 옆에
GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY
를 추가하면 새로운 래코드를 생성할 때 자동으로 기본키가 추가되고 필요하면 직접 지정도 가능합니다.
BY DEFAULT를 ALWAYS로 바꾸면 자동 생성되는 값만 허용되고 직접 입력은 안 됩니다.
다시 selectKey로 돌아와서...
<selectKey>는 <insert>태그 실행 전에 특정 값을 조회해
파라미터 객체에 자동으로 세팅해줄 때 사용하는 기능입니다.
우리는 이것을 시퀀스의 .CURRVAL를 사용해서 insert 후의 기본키를 가져오는데 쓸건데
만약 직접 시퀀스를 만들어 썼다면 시퀀스 이름을 직접 지정했을테니 찾기 쉬울 겁니다.
하지만 위와 같은 방법으로 자동 생성되는 시퀀스를 썼다면 이름이 ISEQ$$_숫자로 되어있어서
어느 테이블의 시퀀스인지 쉽게 찾기 어렵습니다.
이 경우 아래 쿼리를 사용하면 원하는 테이블의 기본키 시퀀스를 확인할 수 있습니다.
SELECT table_name, column_name, generation_type, sequence_name
FROM user_tab_identity_cols
WHERE table_name = '테이블명';
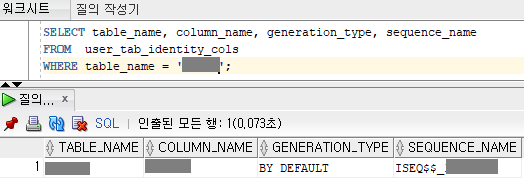
시퀀스를 확인했다면 <insert> 태그 안에 아래와 같이 <selectKey> 태그를 추가해 줍니다.
<selectKey keyProperty="{반환할 변수명}" resultType="int" order="AFTER">
SELECT {시퀀스명}.CURRVAL FROM dual
</selectKey>
해석하자면 시퀀스의 현재값(.CURRVAL)을 반환할 변수명에 int형으로 담으라는 것인데
order="AFTER"이기 때문에 insert를 진행한 후에 실행되어 직전에 생성된 레코드의 기본키를 반환할 것입니다.
order="BEFORE" 옵션을 쓰고 시퀀스의 다음값(.NEXTVAL)을 쓸 수도 있는데
이때는 값 반환과 동시에 시퀀스값도 오르기 때문에
반드시 이때 받은 다음값을 insert할 때 기본키로 삽입해주어야 합니다.
안 그러면 NEXTVAL때 한 번 오르고 기본키를 자동으로 생성받을 때 또 한 번 오름으로써
총 2번씩 기본키가 오르므로 주의해야 합니다!😥(유경험자)
2️⃣ <selectKey> 태그 활용 - 일반 select문 사용
만약 시퀀스를 사용하지 않는다면 어떻게 해야 할까요?
간단합니다!
insert 실행 전에 조회한 특정값을 파라미터 객체에 세팅해주는 기능답게
해당 테이블의 최고 기본값을 알아낸 뒤 거기에 1을 더해주면 되겠죠!
<insert id="dao명칭" parameterType="map" useGeneratedKeys="false">
<selectKey keyProperty="기본키 필드명" resultType="int" order="BEFORE">
SELECT NVL(MAX(기본키 필드명), 0) + 1 AS 기본키 필드명
FROM 테이블명
</selectKey>
INSERT INTO 테이블명 (
기본키 필드명, ...
)
VALUES (
#{기본키 필드명}, ...
)
</insert>
시퀀스를 사용하지 않으니까 기왕 받아온 다음 기본키 값을
기본키 필드에 파라미터로 넣어주시는 것도 잊으시면 안됩니다!😉
3️⃣ oracle의 RETURNING INTO 구문 활용
Oracle의 RETURNING INTO 구문은 INSERT, UPDATE, DELETE문을 실행할 때
영향을 받은 레코드의 특정 필드값을 바로 변수로 담아주는 기능입니다.
아래와 같이 쿼리를 작성하면 insert할 때 영향을 받은 레코드(생성된 행)의 기본키를 반환받겠죠.
<insert id="dao명칭" parameterType="파라미터 타입">
INSERT INTO 테이블명 (기본키 필드명, ...)
VALUES (시퀀스명.NEXTVAL, ...)
RETURNING 기본키 필드명 INTO #{기본키 필드명}
</insert>
단, JDBC 드라이버와 MyBatis 버전에 따라 RETURNING INTO 구문 지원여부가 달라
충분히 테스트를 해보고 써야 합니다.
저는 프로젝트가 아직 호스팅 되기 전이라 환경이 바뀔수도 있다고 해서
일단은 selectKey를 사용했습니다.
시퀀스 기반이라면 selectKey가 가장 안정적이지만,
RETURNING INTO는 오라클의 고유기능이라 성능상 유리할 때가 있어서
둘을 잘 비교해보고 선택해서 써야 겠습니다.
🎺 GROUP BY 규칙
오라클은 MySQL보다 규칙을 꼼꼼하게 따지는데
대표적으로 group by를 수행할 때 select절에 나오는 모든 필드가
집계 함수(count, sum, ...) 또는 group by절에 포함되어야 한다는 규칙이 있습니다.
아래와 같은 쿼리를 작성했다고 해보죠.
SELECT p.*, COUNT(*) cnt
FROM product p JOIN comments c ON c.no = p.no
GROUP BY p.no;
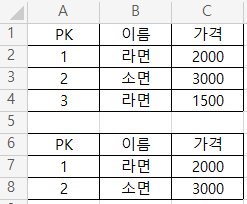
MySQL이라면 상품 테이블(product)의 각 행에 댓글 갯수만 추가해서 결과를 반환해줬을 겁니다.
하지만 오라클은 group by 규칙을 꼼꼼히 따지므로
no외의 모든 필드가 group by에 들어있지 않으면 오류로 판단합니다.

그래서 모든 필드를 group by절에 언급해주거나
SELECT p.*, COUNT(*) cnt
FROM product p JOIN comments c ON c.no = p.no
GROUP BY p.no, p.name, p.price, ...;
좀 더 간결하게 p.*을 쓰지 않고 필요한 필드만 언급해주거나
SELECT p.no, p.name, COUNT(*) cnt
FROM product p JOIN comments c ON c.no = p.no
GROUP BY p.no, p.name;
서브쿼리를 활용해 집계 결과만 따로 뽑아낼 수 있습니다.
SELECT p.*, c.cnt
FROM product p
JOIN (
SELECT no, COUNT(*) AS cnt
FROM comments
GROUP BY no
) c ON p.no = c.no;
사실 따지고보면 오라클의 방식이 맞을 수 있습니다.
저야 습관이 되어서 기본키를 기준으로 group by절을 사용하지만
쿼리에 익숙하지 않은 사람이 고유값인 기본키가 아닌 다른 필드를 기준으로 group by절을 사용한다면
MySQL의 경우 묶는 행들의 가장 첫번째 행만 기준으로 남기므로
의도한 데이터가 아닐 확률이 생깁니다.
📯 NULL의 정렬
오라클에서 또 한 번 기함했던 것이 NULL값의 정렬입니다.
사실 이런 정렬 문제 때문에 문자열에는 빈값( '' )을 기본으로 두고 숫자는 0을 기본으로 두지만
오라클에서는 문자열이 빈값( '' )일 때 자동으로 NULL처리 하므로 완전히 배제하기가 힘듭니다.
그런 와중에 오라클에선 NULL을 가장 큰 값으로 취급하므로
내림차순 정렬 시 null이 가장 상위에 위치하게 됩니다.

이것이 싫다면 NULLS LAST 를 추가해
ORDER BY 필드명 DESC NULLS LAST
으로 사용해주면 null값을 가장 아래로 보낼 수 있습니다.
FIRST로 바꿔서 반대로 가장 최상위로 보낼 수도 있습니다.
🔥 결론
오라클은 쓰면 쓸 수록 쿼리 규칙에 매우 까다롭다는 생각이 듭니다.
물론 그만큼 조회가 빠른 점은 장점이라고 할 수 있겠지만
지금 저희 프로젝트 처럼 작은 서비스를 만들 때는 가끔 힘겹게 느껴지네요...

하지만 저희 팀은 대규모 서비스를 운영하는 회사를 목표로 하고 있으니까.
이 경험이 나중에 도움이 될거라고 생각하면 아주 조금 재밌게 봐줄수도 있을 것 같아요!
틀린그림 찾기 같기도 하고...ㅎㅎ
차이점이 생각보다 많아서 나중엔 하나의 포스팅으로 정리 해봐야겠네요!😎✨
'TIL > TIL 챌린지' 카테고리의 다른 글
| [현대이지웰 Java 풀스택 개발자 아카데미 6월] TIL 22차 - 리엑트 api BaseUrl 관리 전략 (0) | 2025.12.16 |
|---|---|
| [현대이지웰 Java 풀스택 개발자 아카데미 6월] TIL 21차 - DTO 미사용으로 인한 API 필드명 스타일 불균일성 이슈 (1) | 2025.12.09 |
| [현대이지웰 Java 풀스택 개발자 아카데미 6월] TIL 19차 - 프로젝트에서 MyBatis 사용하기 (feat.Oracle) (0) | 2025.11.25 |
| [현대이지웰 Java 풀스택 개발자 아카데미 6월] TIL 18차 - MSA (0) | 2025.11.18 |
| [현대이지웰 Java 풀스택 개발자 아카데미 6월] TIL 17차 - 오라클과 MySQL의 차이 (0) | 2025.11.11 |



